Bazel builds can be sped up significantly by caching build outputs. A remote cache helps reduce the running time of your builds on CI runners by effectively reusing Bazel build outputs. This post introduces you to the options available for deploying a self-hosted Bazel remote cache.
How Bazel remote caching works
Bazel’s remote caching is surprisingly simple. Based on the HTTP/1.1 protocol, it's described in the official docs as follows:
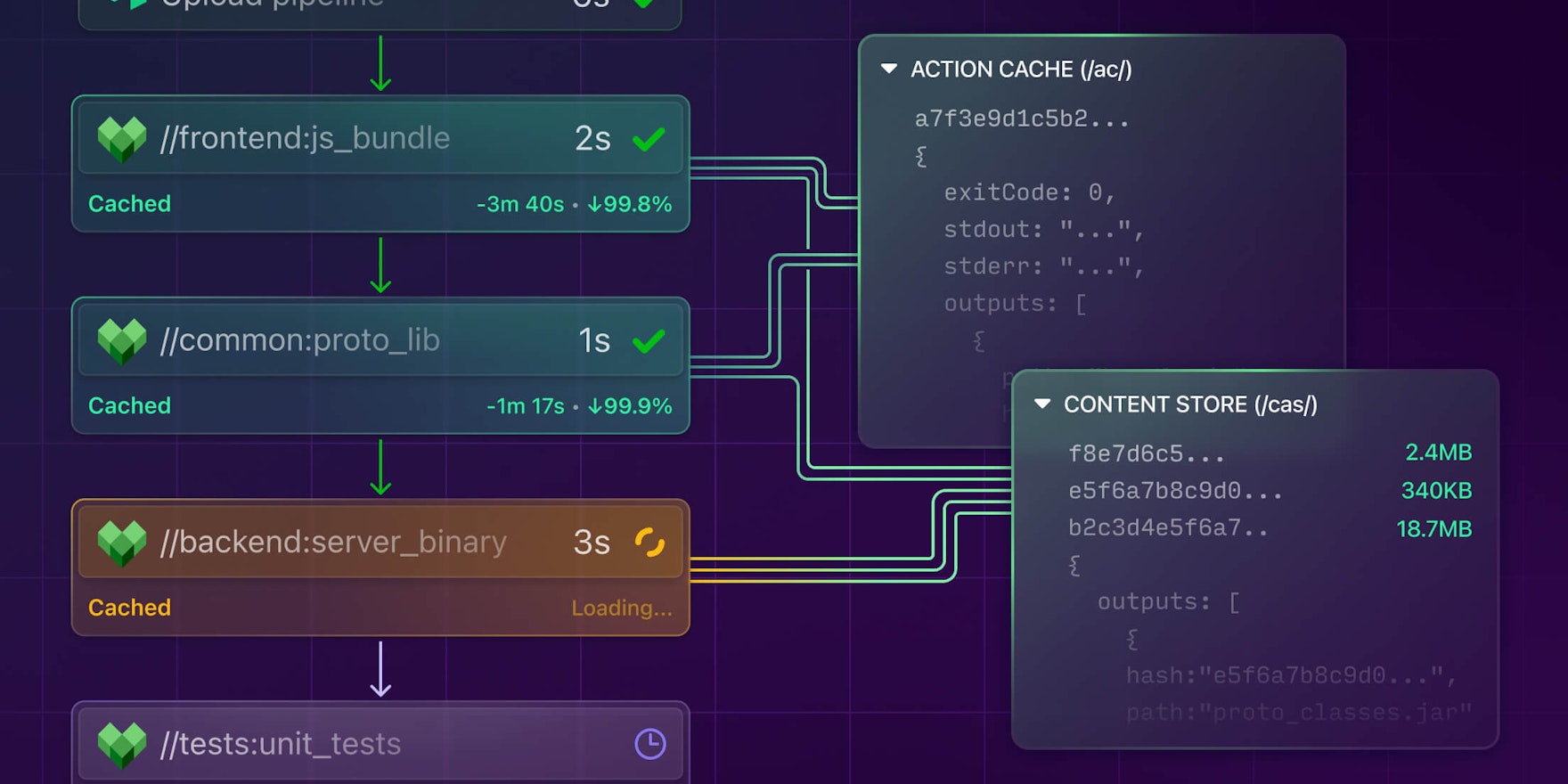
Binary data (BLOB) is uploaded via PUT requests and downloaded via GET requests. Action result metadata is stored under the path
/ac/and output files are stored under the path/cas/.
The remote cache stores two types of data:
- The action cache, which is a map of action hashes to action result metadata
- A content-addressable store (CAS) of output files
Successful remote cache hits will appear in the status line, which might look like this:
INFO: Elapsed time: 1.727s, Critical Path: 1.19s
INFO: 25 processes: 2 remote cache hit, 23 internal.Here, out of 25 processes, 2 were remote cache hits, so 23 were executed locally.
We highly recommend reading the overview section in the official docs to learn more about remote caching in general. For guidance on how best to identify cache hits and misses, see the remote-cache debugging docs.
What is remote caching?
Remote caching is a feature of Remote APIs. Remote APIs is a collection of APIs that enable large scale distributed execution and caching on source code and other inputs. The APIs are categorized as Remote Execution, Remote Asset and Remote Logstream.
There are several clients, including Bazel, that use servers that support the remote execution APIs from REAPI. These clients are free to talk to any server that can support remote execution for distributed execution and/or caching.
Self-hosting a remote Bazel cache with bazel-remote
In this post, we’ll focus on bazel-remote, since it’s a cache-only service. In other words, bazel-remote only implements the caching APIs from the remote execution collection of APIs. Also note bazel-remote is not the only open-source service that can support remote caching for Bazel. Have a look at the other open-source remote execution servers in the official remote APIs GitHub repository.
bazel-remote is a simple Go-based service. It can be run as a container or in its raw binary form on a VM with a local disk as its primary method of persistence. In addition to writing to a local disk, it also supports writing (asynchronously) to Amazon S3, Google Cloud Storage, Azure Storage, or even another bazel-remote instance as a proxy backend.
Here’s what a simple example of deploying bazel-remote would look like:
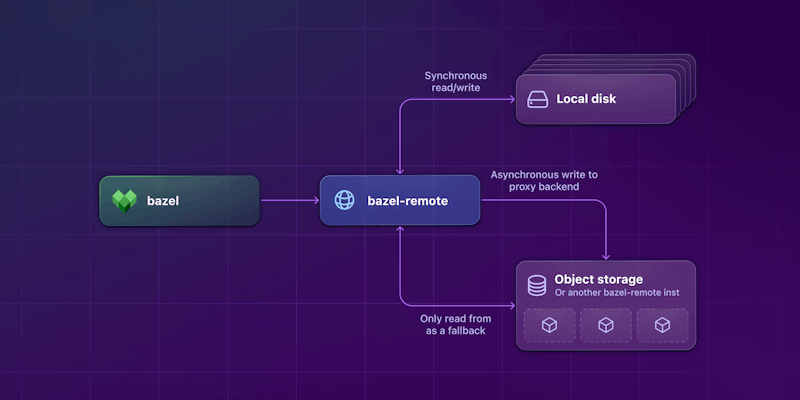
How the Bazel CLI and bazel-remote service write to and read from different storage backends.
Deploy the bazel-remote service with Terraform or Pulumi
To make it easy to deploy bazel-remote on AWS, we've created two infrastructure-as-code examples, one using Terraform and the other Pulumi. The repository containing both examples is available on GitHub at https://github.com/buildkite/bazel-remote-cache-aws-iac-example.
Both versions set up the same infrastructure components:
- An ECS cluster using the AWS Fargate capacity provider
- A
bazel-remoteECS service that utilizes:- AWS Firelens with a FluentBit sidecar container definition
- A load-balancer target group attachment
- A security group for access to
bazel-remote - An EBS volume managed by ECS
We chose ECS on Fargate as the compute platform on AWS because of its simplicity and its capability to scale services easily. Moreover, it’s possible to use an EFS volume instead of an EBS volume just as easily—although we recommend starting with the EBS volume. Services are always updated using a blue/green strategy, which is useful when updating bazel-remote to a newer version without causing interruptions.
Before you can run either of the IaC code samples to set up bazel-remote on ECS, make sure you have the right AWS credentials with permissions to the following resources:
- IAM roles, policies and the ability to pass a role to ECS
- CloudWatch log groups and log streams
- ECS clusters, services, and task definitions
- EC2, including VPCs, target groups, load balancers, and security groups
To deploy with Terraform, make sure you've applied your AWS credentials in the usual way (e.g., with environment variables), then change to the terraform folder in the repository and run:
terraform init
terraform plan
terraform applyBy default, this will write to a local Terraform state file. If you'd prefer to use HCP Terraform Cloud, follow the tutorials to set up the cloud workspace so you can save your state on TF Cloud instead of managing it in Git version control.
Alternatively, to deploy with Pulumi, once again make sure you've applied your AWS credentials properly, change to the pulumi folder in the repository, and run:
pulumi stack init dev
pulumi preview
pulumi upUnlike Terraform, Pulumi writes its state to Pulumi Cloud by default. If you'd prefer to write to a local file, use pulumi login --local first, then follow the same steps.
When the deployment completes, both the Terraform and Pulumi versions will expose the DNS name of the load balancer as outputs:
terraform output dns_name
bazel-remote-1818996606.us-west-2.elb.amazonaws.com%
pulumi stack output dnsName
web-lb-07ad29a-136960774.us-west-2.elb.amazonaws.comTo use the newly-created service as remote cache, format the DNS name as http://${dns_name} and use it in your bazel command-line client with the --remote_cache flag:
bazel build //... --remote_cache "http://$(terraform output -raw dns_name)"
bazel build //... --remote_cache "http://$(pulumi stack output dnsName)"And thats it! You're now up and running with a scalable Bazel remote cache service on AWS.
The next section will walk you through further configuration options you may want to consider as next steps.
Configuring bazel-remote
Many of these configuration recommendations were compiled from questions and experiences reported from users of bazel-remote and their experience of running it at scale. See bazel-remote#786, for example.
Authentication
bazel-remote supports Basic authentication using an .htpasswd file. You should ensure you're using HTTPS in this case since the username/password will otherwise be transmitted in clear text.
If you plan to deploy the service internally in your corporate network that is not reachable over the internet, you may be able to skip this.
Compression
While there is no extra configuration necessary to achieve this, we have included this as a separate section to add more context on compression behavior.
bazel-remote uses Zstd compression by default, but it can be disabled with the flag --zstd_implementation. Running bazel-remote with compression enabled will increase the effective cache size of the remote cache, but you can also tell your Bazel client to upload already-compressed blobs to achieve even better network performance.
To tell the Bazel client to use compression with the remote cache service, pass the flag --remote_cache_compression (or --experimental_remote_cache_compression if you're using Bazel v6). Additionally, it's also recommended that you set a threshold for when compression should be triggered, so that some small artifacts aren’t needlessly compressed, which can increase memory usage on your Bazel build runners. To set this threshold, pass the flag --experimental_remote_cache_compression_threshold with a value of 100 (starting in Bazel v7, this is the default value), which appears to be a sort of sweet spot for compression effectiveness, to your Bazel client. You may tune this value later based on your needs and observations.
Max disk cache size
The --max_size flag allows you to set the ceiling for the cache regardless of the size of the disk. This ceiling lets bazel-remote evict some items using an LRU eviction policy. Be sure to set this to a reasonable value based on your disk size.
Networking
Consider the location of the remote cache and provision the instance as close as possible to, or even in the same VPC as, your Bazel build runners.
Other performance considerations
It is recommended that you start with a simple cache setup for a build and observe its efficacy before trying to optimize the setup, as the optimization depends on the problems you may run into.
While there isn’t any official recommendation for how to run bazel-remote effectively for different types of scenarios, we’ve collected some information based on user feedback from the repository. Here’s a collection of information that might be useful for your deployment.
Load balancing
It might be tempting to load-balance multiple bazel-remote instances each with their own disk cache. Do not do this unless you can ensure that cache requests from the Bazel client can be routed to the same bazel-remote instance for every request in the course of a single build. You might be able to use a network file system instead of a local disk, for example, JuiceFS, Amazon EFS, or similar services.
Many load balancers offer session affinity or client stickiness which allows you to route a request to a specific backend server. However, that feature requires clients to persist cookies (e.g., web browsers) that are sent back to the server with every subsequent request. So the feature is ineffective with Bazel.
Partitioned caching
Instead of using a single bazel-remote cache for every type of build your team may be running, consider running an instance, say, for each platform that you are building for, or identify the builds with large artifacts, and perhaps use a dedicated instance for those and isolate the others to different dedicated cache instances.
Tiered caching
Whereas partitioned caching ensures that you have dedicated instances for certain types of builds, tiered caching is where you might have smaller bazel-remotes that use a central, larger bazel-remote instance as an HTTP proxy backend. Remember that bazel-remote can use object storage or even another bazel-remote instance as a proxy backend to fallback to. (The words “larger” and “smaller” here refer to the disk size and not the compute size.)
More self-hosting options: cloud object storage
While there may be other ways to self-host a remote cache that satisfies Bazel’s HTTP caching protocol, using an object storage service such as Amazon S3, Google Cloud Storage, or Azure Blob Storage might be even simpler.
Specifically, using a Google Cloud Storage bucket might be the simplest compared to others, since the Bazel client supports specifying a Google credentials file for authentication. This means you don't need another service in front of object storage to handle authentication (i.e., some sort of a reverse proxy), as would be the case for Amazon S3 and Azure Blob Storage.
If you are interested in using Amazon S3 as a Bazel remote cache, check out this example, which uses Amazon S3 and CloudFront, and also supports HTTP Basic authentication.
Next steps
Using a remote cache with Bazel can dramatically reduce your build times—especially with large and complex projects that produce a lot of infrequently changing build artifacts.
If you're using Bazel in production, chances are you'll need a delivery platform that can help you manage the scale and complexity that Bazel projects so often require. As a flexible and massively scalable platform, Buildkite is an especially good fit for Bazel—in fact, the Bazel team itself even uses Buildkite to ship Bazel! A few suggestions to keep the learning going:
- Learn how the Bazel team built its CI system on top of Buildkite
- See how to use Bazel with Buildkite dynamic pipelines to fine-tune your workflows using Bazel's knowledge of the dependency graph
- Brush up on your
bazel queryskills - Learn more about Bazel and Buildkite in the docs
How Bazel built its CI system on Buildkite
Register to watch the webinar

- Recorded on
- March 17, 2025
- Length
- 19 minutes